
The Sawtooth: Why Your AI Forgets Why It Believes Things (Revised)
This is a revised edition of the original Sawtooth post from February 2026. The core observation is unchanged — context compaction destroys justification chains, leaving beliefs floating free of their foundations. What’s changed is the solution: instead of file-based workarounds, we now have a full external epistemic memory system that makes compaction structurally irrelevant to knowledge persistence.
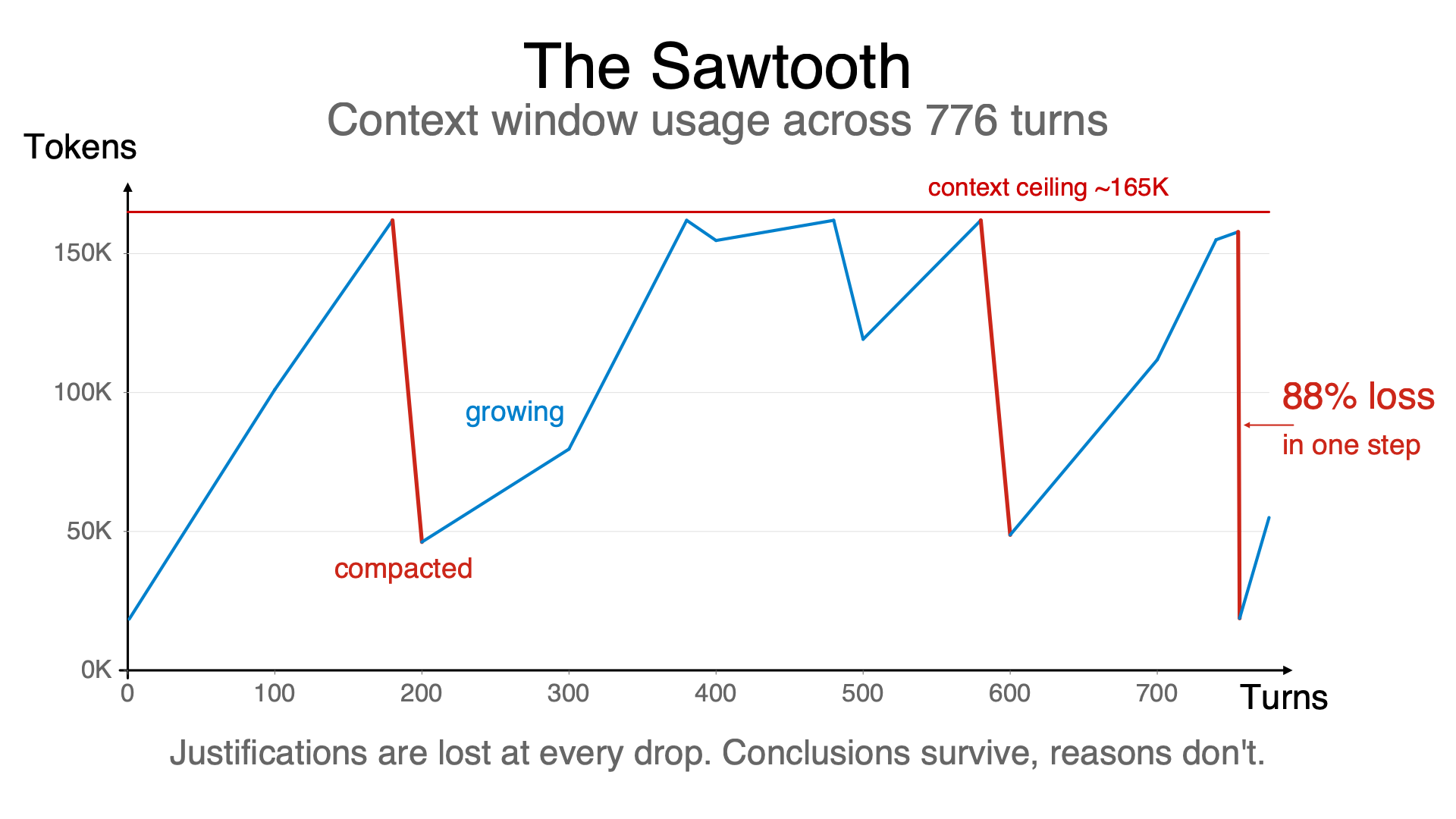
I measured the context window usage across a 776-turn session with one of my research agents. The pattern was unmistakable:
Turn 1: 18,463 tokens
Turn 100: 101,082 tokens (growing)
Turn 200: 46,198 tokens (compacted)
Turn 300: 79,646 tokens (growing)
Turn 400: 154,735 tokens (near ceiling)
Turn 500: 119,187 tokens (compacted)
Turn 600: 48,753 tokens (compacted again)
Turn 700: 111,803 tokens (growing)
Turn 776: 54,984 tokens (post-compaction)
Context grows until it hits the ceiling (~165,000 tokens), then drops through lossy compression, then grows again. A sawtooth wave. The sharpest drop I measured:
Turn 755: 157,844 tokens. Turn 756: 18,722 tokens. An 88% loss in a single step.
What Gets Lost
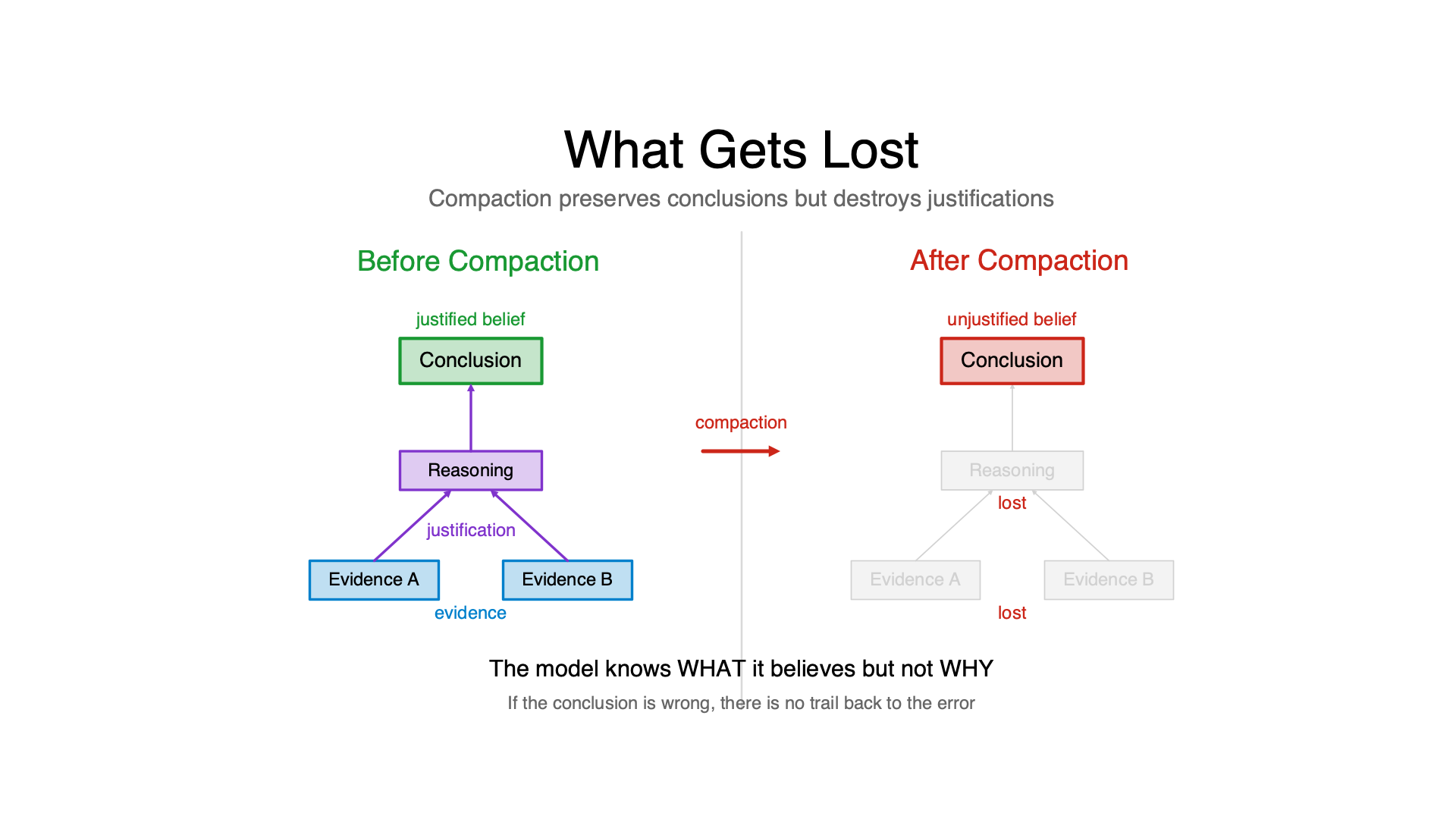
Before compaction, the context contains:
- Justifications — why conclusions were reached
- Dependency chains — evidence → reasoning → conclusion
- Retraction history — what changed and why
- Contextual disambiguation — what claims meant when they were made
After compaction: the model retains conclusions but loses justifications. It knows what it believes but not why. It knows a value is correct but not which calculation produced it. It knows a hypothesis was rejected but not which test falsified it.
This isn’t just information loss. It’s a specific kind of information loss that destroys the ability to correct errors.
Doyle’s Summarization Problem (1979)
In 1979, Jon Doyle identified summarization as the key unsolved problem for truth maintenance systems: how do you compress a justification network — the full history of beliefs and their dependencies — without losing the ability to correct errors?
That’s exactly what context compaction does. It compresses the conversation history into a summary. The summary preserves conclusions (they seem important) and drops justifications (they seem like intermediate work). But justifications are what you need when a conclusion turns out to be wrong.
When the model compacts “X is true because of evidence A, B, and C” into “X is true,” you’ve lost the ability to revisit X when evidence A is invalidated. The belief persists without its foundation. In TMS terms, it’s an unjustified belief — a conclusion floating free of the reasoning that produced it.
Three Consequences
1. Beliefs outlive justifications. A belief formed before compaction persists after, but its supporting evidence was destroyed. If someone later asks “why do you believe X?” the model confabulates a justification rather than admitting it doesn’t remember. The confabulated justification may be wrong.
2. Implicit circumscription. After compaction, the model treats the summary as the complete state of the world. Anything not in the summary is implicitly retracted — not through principled belief revision, but through lossy compression. The model doesn’t know what it forgot.
3. Error correction breaks. If an error was incorporated into the summary (believed to be correct at compaction time), there’s no trail back to the source. Dependency-directed backtracking — the standard technique for tracing errors to their root cause — requires the dependency chain to exist. Compaction destroys it.
The Numbers
I measured compaction across 33 sessions in the research programme:
- Peak context ceiling: 160,000-167,000 tokens (uniform across repos)
- Effective working memory: 50,000-120,000 tokens between compactions
- Fixed overhead: ~18,000 tokens (role definition, system prompt)
- Available for work: 32,000-102,000 tokens
- Compaction frequency: Every 100-200 turns in active sessions
- Information loss per compaction: 50-88%
- Cache hit rates: 99.6-100.0% (space cost is real, compute cost is amortized)
After several compaction cycles, accumulated information loss becomes significant. Very long sessions (700+ turns) may produce lower-quality reasoning than fresh sessions that explicitly load relevant context.
The Solution: External Epistemic Memory
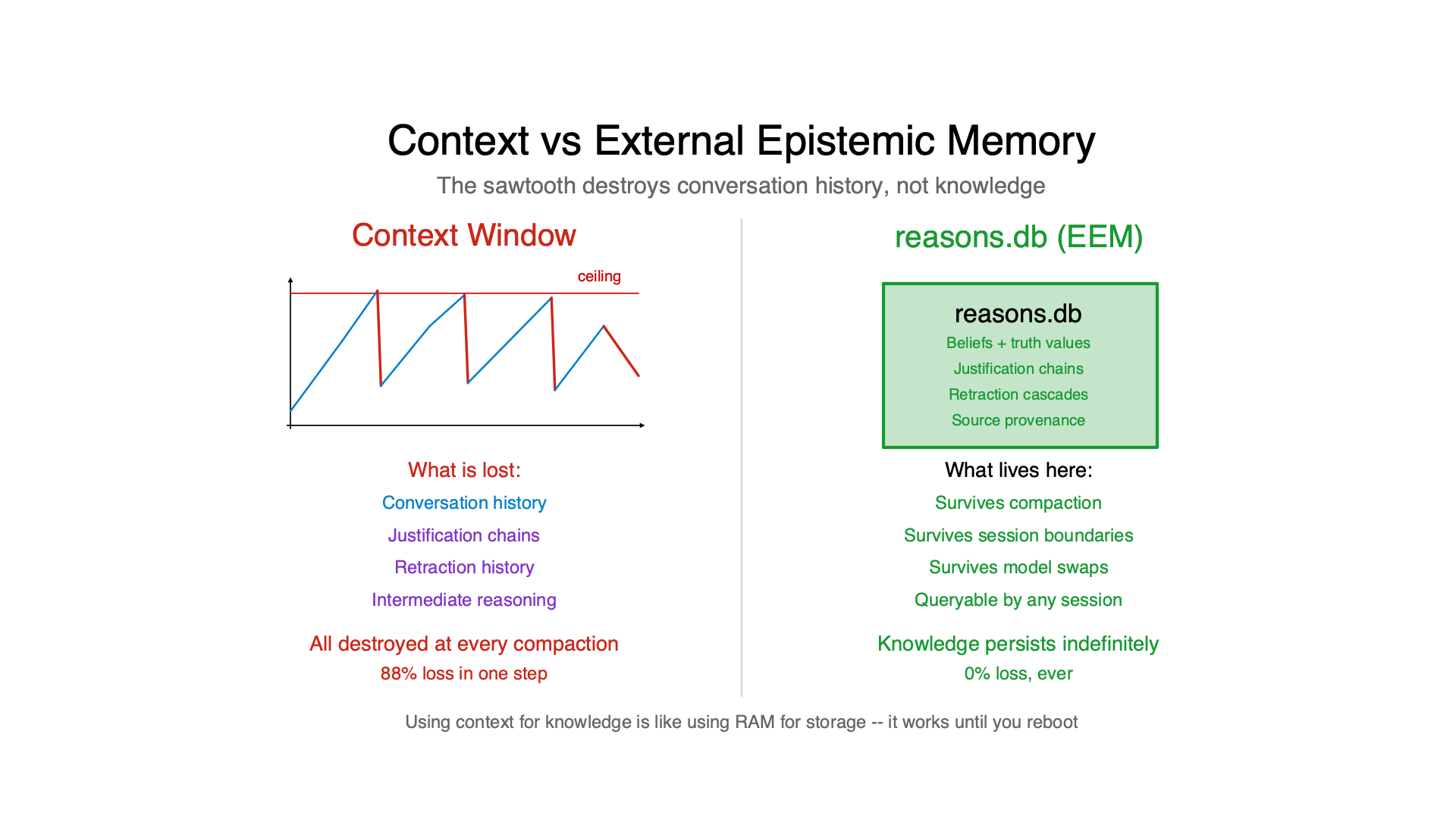
The original post described a workaround: beliefs compact — a token-budgeted summary of belief state written to a file. That was a band-aid. The real solution is to move knowledge out of context entirely.
External epistemic memory stores beliefs in a SQLite database (reasons.db) that exists completely outside the context window. Every belief has its justification chain, truth value, source provenance, and dependency links — all in the database, not in the conversation. When context compacts, the beliefs survive untouched. The sawtooth affects conversation history. It does not affect knowledge.
# Knowledge lives in the database, not the context
$ reasons add crash-recovery-must-preserve-invariants \
"Crash recovery must preserve every invariant the normal write path maintains" \
--sl write-path-invariants,recovery-design
$ reasons show crash-recovery-must-preserve-invariants
ID: crash-recovery-must-preserve-invariants
Text: Crash recovery must preserve every invariant...
Status: IN
Justified by: write-path-invariants, recovery-design
Dependents: sstable-recovery-correct, compaction-safe-under-crash
After compaction, the model may forget the conversation that produced this belief. But reasons show reconstructs the full justification on demand. reasons explain traces why a belief is IN or OUT. reasons search finds relevant beliefs by semantic similarity. The knowledge is queryable at any time, by any session, with any model.
The model’s job shifts from remembering knowledge to querying knowledge. This is a fundamental architectural change. Instead of trying to preserve justification chains through lossy compression (an unsolved problem), you sidestep the problem entirely by never putting justification chains in the context in the first place.
Why This Matters More Than I Thought
The original post framed compaction as a practical nuisance. Three months of building 40+ expert knowledge bases revealed it’s a structural bottleneck that limits every single-session LLM workflow.
The dirty pipeline math: An 85% accurate model across 5 reasoning stages compounds to 44.4% end-to-end accuracy. Context compaction makes this worse — each compaction event can corrupt a reasoning chain, reducing the effective accuracy of subsequent stages. With external epistemic memory, the derive-then-review architecture bypasses compaction entirely and converges to 98.2% in 5 rounds.
The derive-review cycle: Each round of derive-then-review catches 13-37% of bad beliefs. This cycle can span multiple sessions and multiple compaction events without loss — because the beliefs, justifications, and retraction history live in the database, not in the context. A fresh session picks up exactly where the previous one left off.
Cross-session continuity: The original post noted that “files survive compaction, conversation doesn’t.” External epistemic memory goes further: the database survives not just compaction but session boundaries, model swaps, and provider changes. A belief derived by Claude on Tuesday can be queried by Gemini on Wednesday. The knowledge is model-independent.
The 88% vs 33% gap: The controlled experiment that validated EEM — same 50 questions, same model, with and without the belief network — is fundamentally a measurement of what happens when knowledge moves from context (subject to compaction) to database (immune to compaction). The 55-point accuracy gap is the cost of keeping knowledge in the wrong substrate.
The Sawtooth Is a Symptom, Not the Disease
The original post treated compaction as the problem. The real problem is that the context window was never the right place for persistent knowledge. Using context for knowledge is like using RAM for storage — it works until you reboot. Compaction is just the reboot.
Every workaround that tries to preserve knowledge through compaction — summarization prompts, checkpoint files, compact belief snapshots — is fighting the wrong battle. The solution isn’t better compression. It’s externalizing the knowledge so compression doesn’t matter.
The sawtooth still exists. The context still fills and compacts. But when the knowledge lives in reasons.db with full justification chains, compaction destroys conversation history — not knowledge. That’s the difference between losing your notes and losing your notebook.
Practical Advice (Updated)
For any session length: Use external epistemic memory. Don’t wait until you hit the ceiling. Every belief worth keeping should go into reasons.db the moment it’s established — not after compaction threatens it.
# Add beliefs as you work, not as a checkpoint
reasons add finding-name "The claim you just established" --sl evidence-a,evidence-b
# Query at any time, in any session
reasons search "the topic you need"
reasons explain finding-name
For long-running projects: Build a belief network that accumulates across sessions. Each session reads from and writes to the same database. The 40+ expert knowledge bases we’ve built span dozens of sessions each — no single session could have produced them, but each session contributed incrementally.
For automated pipelines: The derive-review-repair loop runs across session boundaries automatically. reasons derive generates new beliefs. reasons review-beliefs evaluates them. Retractions cascade through reasons.db. None of this requires the previous session’s context to be present.
For teams: The database is portable. Share reasons.db via git. Multiple agents (or humans) can read and write to the same belief network. Cross-session, cross-model, cross-team knowledge that doesn’t degrade.
The tools:
- ftl-reasons — External epistemic memory with justified beliefs and retraction cascades
- expert-agent-builder — Automated pipeline from sources to belief network
- EEM Hub — Pre-built experts you can clone and use today
This is a revised edition of the original Sawtooth post from February 2026. The original described the problem and a file-based workaround. This revision describes the structural solution: external epistemic memory that makes compaction irrelevant to knowledge persistence.
Previously: Clay Tablets (Revised), Classical AI (Revised), The Expert Agent (Revised), Metaprogramming With Beliefs (Revised).