
Stop Fine-Tuning, Start Remembering
Your organization wants domain-specific AI.
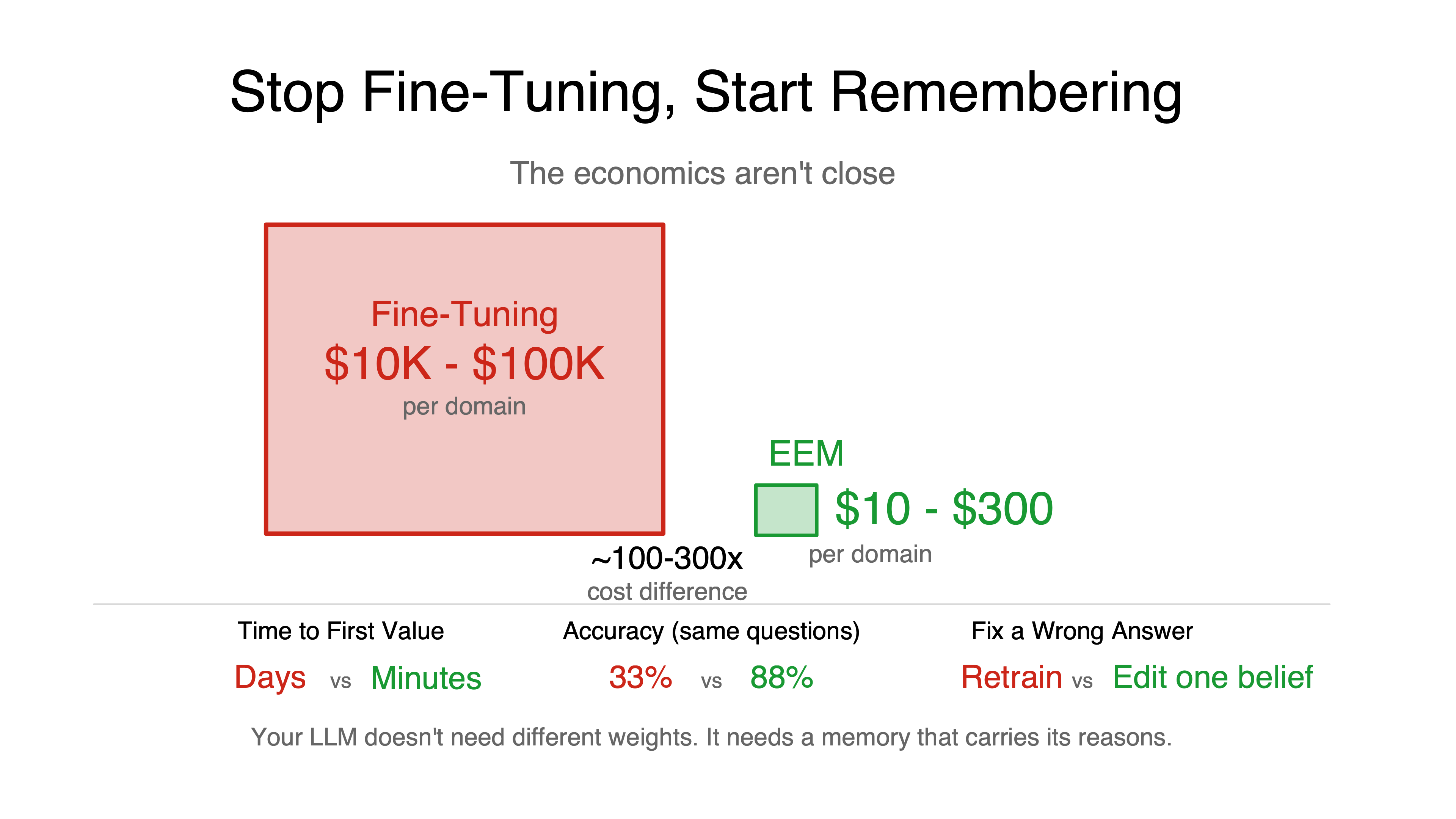 Your team has two options:
Your team has two options:
- Fine-tune the model. Modify the weights so the model “knows” your domain. GPU hours, ML expertise, training pipelines, forgetting risk.
- Give the model external memory. Store domain knowledge in a database. The model reads it at query time. No training, no GPUs, no forgetting.
I’ve spent this year building option 2 — external epistemic memory (EEM). After controlled experiments across 4 model families, 40+ knowledge bases, and production deployments, the economics aren’t close.
The Numbers
I built a knowledge base covering 6 enterprise departments from 5,361 source documents. It produced 13,511 justified beliefs. Total cost: ~$300 at Sonnet pricing.
A single fine-tuning run on a 7B model costs $500–$5,000 in GPU time, requires ML expertise to configure, and produces a model locked to one architecture. The EEM costs less than a team lunch, requires no ML expertise, and works with every model.
| Dimension | Fine-Tuning | EEM |
|---|---|---|
| Construction cost | $10K–$100K+ | $10–$300 |
| Time to first value | Hours to days | Minutes |
| Per-query cost | Model serving | < $0.06/question |
| Adding new knowledge | Retrain (GPU hours) | Add a belief (instant) |
| Removing wrong knowledge | Retrain | Retract one belief |
| Forgetting risk | Nonzero | Zero |
| Model portability | Locked to one architecture | Any model via HTTP |
| Inspectable | No | Read the belief text |
For a medium-sized domain (~100 source documents), the total construction cost is $10–25. Break-even happens after 100–250 queries. An enterprise querying 50 questions per day breaks even in 2–5 days.
Performance
Same 50 domain questions. Same model. Same evaluation rubric. The only difference: does the agent have access to pre-built beliefs?
| Metric | Without EEM | With EEM |
|---|---|---|
| A-grade answers | 33% | 88% |
| Response time | ~350s | 25s |
| Speed | Baseline | 15x faster |
In a head-to-head with the same synthesis model (Gemini 3.1 Pro), switching from raw document search to belief retrieval produced 2.5x better accuracy and 10x faster responses. The retrieval architecture is the only variable.
In a separate controlled eval (55 questions, AAP domain):
| Metric | From Scratch | With EEM |
|---|---|---|
| Cost | $13.61 | $7.25 |
| Tokens | 142,395 | 50,199 |
| MC accuracy | 97.5% | 100% |
| Open-ended recall | 72.9% | 85.6% |
Better accuracy. Half the cost. A third of the tokens.
Smaller Models, Same Results
Here’s the economic multiplier. EEM equalizes model size:
| Configuration | A+B Grade |
|---|---|
| Haiku + EEM | 94–100% |
| Opus + EEM | 98% |
| Opus without EEM | 20–94% |
Haiku is 10–50x cheaper per token than Opus. With EEM, the cheapest model matches the most expensive one. The memory is doing the work, not the model.
Build the EEM once with frontier tokens. Query it forever with the cheapest model that can read. The marginal cost of the 1,000th question is near zero.
You Don’t Even Need an LLM
Fine-tuned knowledge is locked inside model weights. The only way to access it is to run the model on a GPU. EEM knowledge lives in a SQLite database — and any program that can query a database can use it.
A production routing system I deployed replaces two LLM calls with a full-text search over beliefs:
# No LLM. FTS5 keyword search over belief text.
results = reasons_search(user_query, db_path=eem_db)
for belief in results:
if belief["id"].startswith("mart-"):
# Matched a datamart
elif belief["id"].startswith("intent-"):
# Mapped user vocabulary to schema vocabulary
167 beliefs — 8 describing datamarts, 122 describing tables with column names, 26 mapping user vocabulary to schema vocabulary (“bugs” → ISSUETYPE, “VMs” → IS_VIRTUAL). SQLite FTS5 search. Sub-100ms.
| Metric | LLM Routing (before) | EEM Routing (after) |
|---|---|---|
| Latency | 10–30s | <100ms |
| Accuracy | 88% | 96% |
| Infrastructure | Vertex AI credentials | SQLite file |
100x faster. 8 percentage points more accurate. No API credentials. No model serving costs. The per-query cost is effectively zero.
This is a capability fine-tuning fundamentally cannot provide. Knowledge in weights requires GPU inference to access. Knowledge in a database is accessible to LLMs, application code, shell scripts, CI pipelines, and humans reading the text directly.
Catastrophic Forgetting Doesn’t Exist
The entire continual learning field — EWC, OSFT, progressive networks, replay buffers — exists because neural network weights are continuous and interdependent. Updating any weight to learn something new risks degrading everything the model already knows.
OSFT (Nayak et al., 2025) solves this with SVD decomposition of weight matrices, gradient projection into orthogonal subspaces, and a tunable forgetting dial (unfreeze_rank_ratio). It’s a 12-page paper with eigenvalue analysis to manage a tradeoff.
EEM doesn’t have this tradeoff. Adding belief #501 does not modify beliefs #1–500. Each belief is a row in a database. There is no shared parameter space, no optimization surface where old and new knowledge compete.
| Fine-Tuning (OSFT) | EEM | |
|---|---|---|
| Add knowledge | Constrain gradients to low-rank subspace | Add a database row |
| Preserve old knowledge | Freeze singular values, project gradients | Nothing to do |
| Forgetting risk | Nonzero (tunable, never zero) | Zero |
| Time to availability | After convergence (hours) | Immediately |
While building an EEM for Minecraft modding, I could query it while the pipeline was still running. Five mod experiments worked on the first try from beliefs extracted from tutorials. The sixth failed — because a tutorial was wrong, not the system. Claude Code traced it through the belief chain, found the bad source, updated one belief, fixed. Total time to fix: minutes. Total things broken by the fix: zero.
If that had been a fine-tuned model, the fix would be: update the training data, regenerate synthetic data, retrain with forgetting constraints, validate that old capabilities survived, deploy. Hours of compute to fix one wrong fact.
Why Architecture Beats Training
An 85% accurate model across 5 pipeline stages produces correct output 44% of the time. Errors compound multiplicatively (more on this here).
The same 85% model with iterative EEM architecture — derive beliefs, review for errors, retract invalid ones, repeat — converges to 98.2% in 5 rounds.
Getting from 85% to 98% through training requires a ~9x reduction in error rate. That’s a decades-long engineering effort historically. Getting there through EEM architecture is immediate.
Returns on model improvement are linear. Returns on architecture are multiplicative.
When Fine-Tuning Still Wins
EEM is not a universal replacement for training. Training wins for:
- Skill learning. Reasoning patterns, tool-use behaviors, code generation — these are procedural skills that need weight updates. EEM stores what to know, not how to think.
- Style adaptation. Writing voice, formatting conventions — fine-tuning shapes how the model expresses itself. EEM shapes what it knows.
- Native tool use. Training small models to natively query EEMs (via LoRA + GRPO) is itself a training task. The skill of using external memory is best learned through weight updates.
- Non-LLMs. Robotics, computer vision, drone navigation — these learn from sensor data, not text. Training is the only path when the knowledge is perceptual, embodied, or spatiotemporal.
The clean split: train for skills, EEM for knowledge. Train for perception, EEM for propositions. Most “model customization” requests are actually knowledge requests — and for those, EEM wins on every dimension.
Build Your Knowledge Base While You Can
People are losing access to models — rate limits tightening, pricing tiers changing, providers deprecating older models. If your knowledge lives in model weights, losing access to the model means losing the knowledge. If your knowledge lives in an EEM, it survives any change in model availability.
EEM turns model access into a construction tool rather than a dependency. Use the best model you have access to today to extract, derive, and review beliefs. The resulting knowledge base is a SQLite file that works with any model tomorrow — or no model at all. The frontier model is the drill that digs the well, not the well itself.
This is the insurance argument: build your knowledge base now while you still have access to good models. The beliefs persist. The justification chains persist. The model that built them can disappear entirely, and the knowledge remains queryable, inspectable, and useful.
A fine-tuned model is the opposite bet. You’re encoding knowledge into weights that are locked to one architecture, one provider, one moment in time. If the base model is deprecated, the fine-tune dies with it.
The Squeeze
Fine-tuning is being compressed from three directions:
- From above. Frontier models improve faster than fine-tunes can keep up. Each new base model release obsoletes your existing fine-tune.
- From the side. GPU infrastructure accelerates model building from scratch. If you can build a model in hours, fine-tuning becomes a bottleneck.
- From below. EEM eliminates the need to put domain knowledge in weights at all.
Frontier tokens are subsidized below cost by investors. Token prices decrease every quarter. A single ML engineer’s salary buys millions of API calls. The economics of running your own training infrastructure are moving in the wrong direction.
The Bottom Line
| Fine-Tuning | EEM | |
|---|---|---|
| Build cost | $10K–$100K+ | $10–$300 |
| Deploy time | Days | Minutes |
| Fix a wrong answer | Retrain | Edit a line of text |
| Model portability | Locked | Any model |
| Accuracy (same questions) | 33% A-grade | 88% A-grade |
| Forgetting risk | Nonzero | Zero |
| Usable without an LLM | No | Yes |
For domain knowledge — which is what most organizations actually need — EEM is cheaper to build, faster to deploy, easier to fix, portable across models, and produces better results. The economics favor EEM for any domain queried more than ~100 times.
Your LLM doesn’t need different weights. It needs a memory that carries its reasons.
The tools are open source:
- ftl-reasons — The EEM engine
- expert-agent-builder — Build EEM from source documents
- EEM-Hub — Community-built EEMs
Browse a live EEM: expert.ftl2.com/public
Previously in this series: External Epistemic Memory: What It Is and Why It Matters, The Dirty Pipeline, LLMs Don’t Need Bigger Models, They Need Clay Tablets.