
Seven Rules for Building Data-Intensive Systems
These rules come from analyzing 37 reference implementations of concepts from Designing Data-Intensive Applications — storage engines, consensus protocols, replication layers, derived data pipelines.
Each rule addresses a failure mode that emerged independently across multiple subsystems.
None are novel. Kleppmann, Gray, Lamport, and others have written about all of them. What’s notable is how reliably they’re violated even when the implementer knows the theory. They’re phrased as construction principles — things to do from the start — because retrofitting them is consistently harder than getting them right up front.
1. Verify integrity at every format boundary
When data changes format or location — WAL record to SSTable block, in-memory buffer to on-disk page, source table to derived index — verify its integrity on both sides.
What goes wrong: Teams protect the write path with checksums but skip verification during compaction, backup, replication, and read-back. Corruption enters through the unguarded transitions and propagates silently through every downstream consumer. By the time it’s detected (usually by an end user), the uncorrupted version has been garbage collected.
Do this:
- Checksum data at write time. Verify at every subsequent read, including internal reads (compaction, merge, hint file generation).
- Cover the full record — metadata, routing headers, and payload — not just the payload. A correct value with a corrupted key is still corruption.
- Don’t silently skip corrupted records. Log with enough context to investigate, or halt and let the operator decide. Silent data loss is worse than a noisy failure.
- Design a corruption recovery path before you need one. “Restore from backup” is a recovery path. “We’ll figure it out” is not.
2. Test under the failure model you claim to tolerate
If your system claims partition tolerance, test it under network partitions. If it claims crash recovery, kill the process mid-operation and verify recovery. If it claims Byzantine fault tolerance, inject Byzantine faults. Testing exclusively under clean, synchronous conditions makes your safety claims unfalsifiable.
What goes wrong: Distributed protocol tests use synchronous, in-process message delivery with deterministic ordering. Every message arrives, in order, immediately. The tests pass — and they would pass even if the protocol had a fundamental safety violation that only manifests under reordering or delay. The team ships with false confidence.
Do this:
- Build a chaos layer into your test harness from day one: message reordering, duplication, delay, loss, and network partitions. These aren’t edge cases — they’re the entire reason you chose a distributed protocol.
- For crash recovery:
kill -9at random points during write operations, then verify consistent recovery.flush()withoutfsync()is not durable. A clean shutdown test is not a crash recovery test. - For consensus: test leadership transitions under load. The steady-state single-leader path is the easy case. The hard cases are leader failure during a write, split-brain during a partition, and recovery after a partition heals.
- Run long-duration soak tests under sustained concurrent load. Many distributed bugs require specific interleavings that only appear under pressure.
3. Make concurrency assumptions explicit and enforced
If a component requires single-threaded access, enforce it — with a lock, an assertion, or a type-level constraint. If a component is thread-safe, document what “safe” means: can multiple threads read concurrently? Can one thread write while others read? Are compound operations atomic?
What goes wrong: Components silently assume single-threaded access. No lock, no assertion, no documentation. The assumption holds during development because there’s only one caller. Then someone adds a background compaction thread. The component doesn’t fail immediately — it produces subtly wrong results: torn reads, lost updates, corrupted internal state. These bugs are intermittent, hard to reproduce, and usually misdiagnosed as application logic errors.
Do this:
- Default to thread-safe with internal locking. Single-threaded-only components should be the exception and should assert their constraint at runtime.
- Protect both read and write paths. Concurrent reads can observe inconsistent state during writes even if writes are serialized.
- Document the concurrency contract in the type or interface, not in a comment. A comment that says “not thread-safe” is read once and forgotten. A lock that must be held is enforced every time.
- For data structures with iterators: decide whether iteration is a snapshot or a live view, document it, and test it under concurrent modification.
4. Recovery must preserve every invariant the normal path maintains
For every invariant your system maintains during normal operation — monotonic counters, sort order, referential integrity, transaction isolation — verify that crash recovery re-establishes it. If recovery can’t restore an invariant, the invariant isn’t real; it’s a fair-weather guarantee that fails exactly when it’s needed most.
What goes wrong: The normal write path carefully maintains invariants: monotonically increasing sequence numbers, sorted key order, visibility rules for uncommitted writes. Then a crash happens. Recovery replays the log, rebuilds in-memory state, reopens for business — and the recovered state violates the invariants the normal path enforced. Aborted data reappears because abort was a status flag, not a physical delete. Monotonic counters reset to zero because they were never persisted. Sort order breaks because recovery doesn’t validate it.
Do this:
- For every piece of volatile state in a correctness invariant: either persist it durably or re-derive it correctly during recovery. “It’s in memory, it’ll be fine” is not a durability strategy.
- If abort is a status change rather than a physical rollback, recovery must replay the abort status. Otherwise, aborted writes resurrect and become visible.
- Fsync the metadata, not just the data. If your data file is fsynced but your metadata page (root pointer, free list, counters) isn’t, a crash can leave the metadata pointing to garbage.
- Write a specific test for every invariant: crash the system, recover, assert the invariant holds. These tests are unpleasant to write and invaluable when they catch bugs.
5. Design repair to match write-path semantics
If writes can create inconsistency through N different mechanisms, the repair mechanism must understand all N. Partial repair creates a false sense of consistency — the system appears healthy by the metrics that repair checks, while divergence accumulates through the mechanisms it doesn’t.
What goes wrong: The write path accumulates divergence through multiple mechanisms: sloppy quorums that count hints toward the threshold, conflict resolution split across modules (CRDTs here, last-writer-wins there, custom callbacks elsewhere), tombstones with different semantics at each layer. Anti-entropy repair detects key-range divergence via Merkle trees but reconciles using only one mechanism. The others continue diverging, invisibly.
Do this:
- Audit every mechanism that can create divergence between replicas. For each one, verify your repair handles it. If it doesn’t, you have unbounded divergence on that axis.
- Unify tombstone semantics across layers. If your storage engine uses physical deletion, your CRDT layer uses tombstone-with-TTL, and your event log uses soft delete, repair cannot reason about deletes consistently.
- Measure divergence, don’t just repair it. If you can’t answer “how many replicas disagree on how many keys right now,” you can’t tell whether repair is winning the race against write-path divergence.
- Test repair under write load, not on a quiescent system. Repair that converges when writes are paused but falls behind under production rates is not a repair mechanism — it’s a demo.
6. Include a version field in binary formats from day one
Every binary format — wire protocol, storage format, log record, index entry — should include a version field in the first few bytes. The cost is one or two bytes per record. The value is the ability to fix format-level bugs, add integrity mechanisms, and extend the format without a flag-day migration.
What goes wrong: The initial format is designed for the initial requirements. No checksums — we’ll add them later. No extensibility — YAGNI. Fixed field widths — simpler to parse. Then a bug requires a format change: corruption that needs a checksum, a field that needs to be wider, a new record type. Without a version field, every change requires either a full offline migration or a backward-compatibility hack that accumulates forever.
Do this:
- First byte (or first two after a magic number): format version. Always. Non-negotiable.
- Design with alignment boundaries that allow resynchronization after corruption. If a single corrupted byte makes the rest of the file unreadable, the format is fragile. Block-aligned records with magic bytes at block boundaries let recovery skip the corrupted block and resume.
- Include record-level redundancy, not just file-level. A file checksum tells you something is wrong; a record checksum tells you what is wrong and lets you recover everything else.
- Plan for the format to outlive the code that writes it. Document it externally — byte offsets, endianness, invariants. Future you will need to write a recovery tool.
7. Make derived-system consistency prerequisites explicit in the API
If a derived system (materialized view, secondary index, search index, cache) requires specific conditions for consistency — a flush, an old-value capture, a sequence number — enforce those conditions in the API. Implicit consistency contracts become forgotten consistency contracts.
What goes wrong: A CDC-fed secondary index requires two things to stay consistent: the source database must flush so CDC consumers can see changes, and change events must include old values so the index can remove stale entries. Neither is enforced. Developers insert rows without flushing, and the index falls behind silently. The CDC layer emits events without old values, and the index accumulates phantom entries. The system appears to work — queries return results — but the results are wrong in ways that are difficult to detect.
Do this:
- If a flush is required for correctness, either auto-flush on every mutation or return a “dirty” token that the caller must resolve before reading derived systems. Don’t rely on the caller remembering.
- If change events must include before-and-after state, make that a schema requirement. Validate at the producer. An event without old values should fail loudly, not produce a silently inconsistent downstream.
- Provide a consistency check: a way to verify that a derived system matches its source of truth without rebuilding from scratch. Even a row-count comparison catches gross inconsistencies.
- Document the consistency model explicitly: eventually consistent? Bounded lag? What happens during a rebuild? Operators need to know what “consistent” means before they can detect inconsistency.
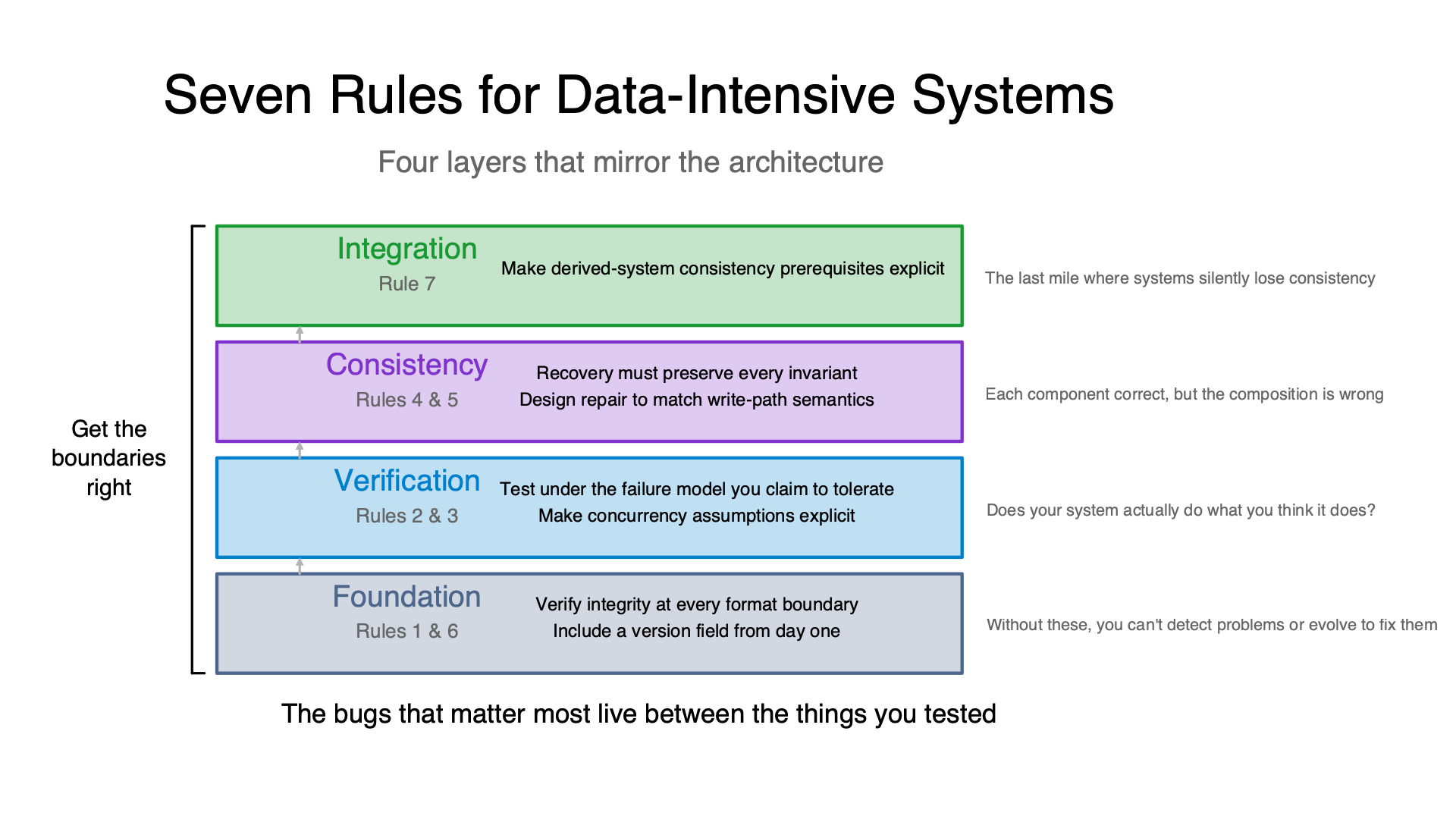
How these rules relate
These aren’t independent. They form layers that mirror the architecture of a data-intensive system:
Rules 1 & 6 (integrity, versioning) are foundation layers. Without them, you can’t detect problems or evolve to fix them. Cheap to implement from the start, expensive to retrofit.
Rules 2 & 3 (failure testing, concurrency) are verification layers. They determine whether your system actually does what you think it does under the conditions it’ll actually face.
Rules 4 & 5 (recovery invariants, repair semantics) are consistency layers. They address the hardest bugs: where each component is correct but the composition is wrong, visible only during failure and recovery.
Rule 7 (derived-system contracts) is the integration layer. The gap between producing data correctly and consuming it correctly — the last mile where many systems silently lose consistency.
The meta-pattern: get the boundaries right. Every rule addresses a boundary — between normal operation and failure, between storage layers, between components, between source and derived data. The bugs that matter most are the ones that live between the things you tested.
These rules were extracted using a belief network built from the reference implementations — 1,405 justified beliefs across 37 subsystems. The network surfaced 30 bugs across 3 rounds of analysis by identifying which observations blocked which derived conclusions. More on that method in a future post.