
Your LLM Knows More Than It’s Telling You
Your LLM knows that list.pop(0) is O(n) in Python.
It knows you need checksums during compaction, not just during writes. It knows that flush() without fsync() isn’t durable. It knows that crash recovery must preserve every invariant the normal write path maintains.
It knows all of this. And it will generate code that violates every one of these principles — because you asked it to “write a solution,” not “find everything wrong with this solution.”
The Problem: Single-Pass Sampling
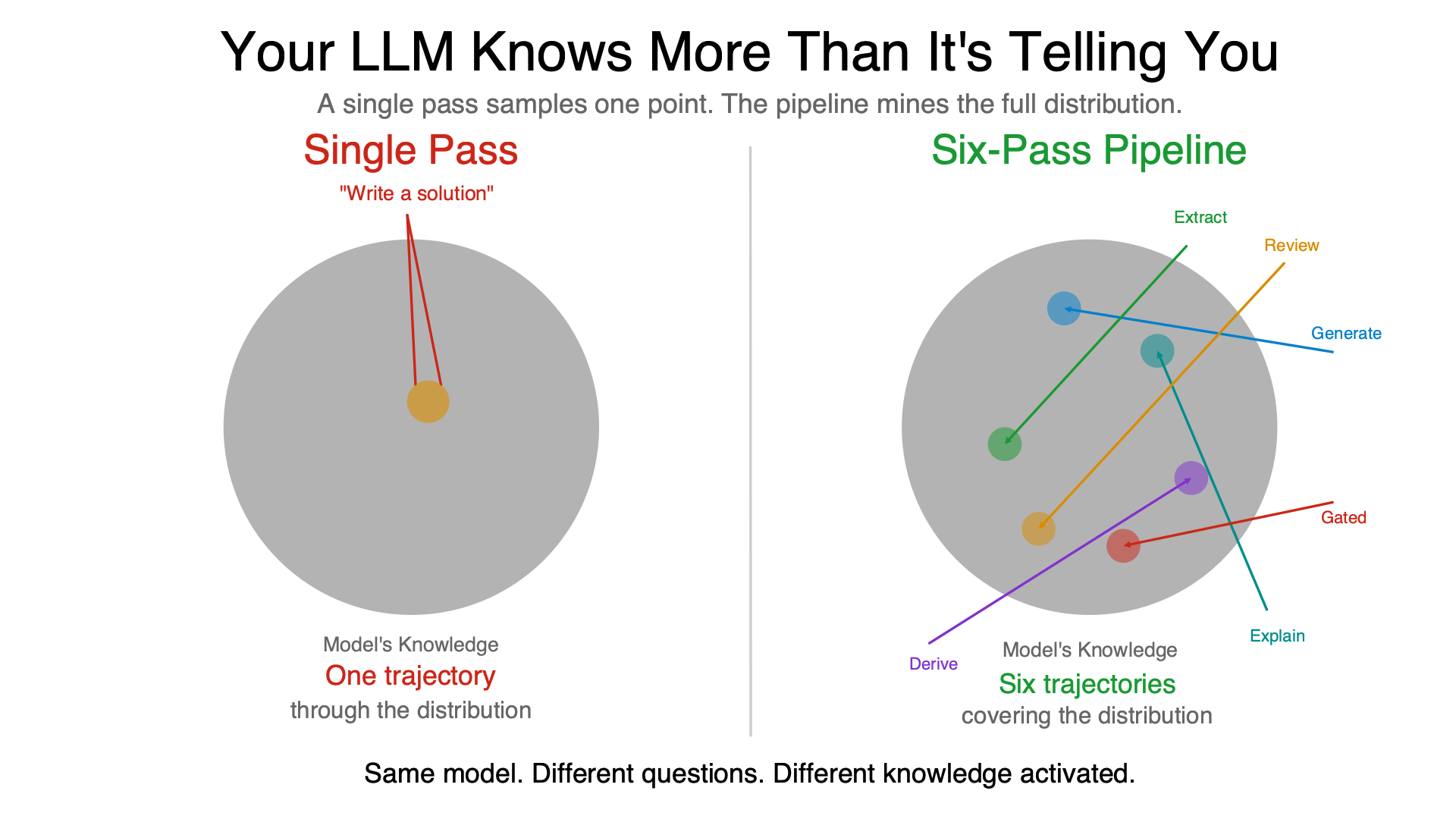
When you ask an LLM to generate code, it optimizes for one objective: produce a working solution. This activates a specific subset of its knowledge — algorithmic patterns, API usage, the happy path. The code it produces is correct for the stated inputs and passes the stated tests.
But “produce a working solution” is only one trajectory through the model’s knowledge. There are others:
- “What edge cases does this miss?”
- “What patterns emerge across 500 solutions like this?”
- “Does this conclusion actually follow from these premises?”
- “What concrete bugs contradict these general claims?”
Each question activates different knowledge. The model that generates a bug at step 1 can find that bug at step 5 — because step 5 asks a different question.
The Evidence
I ran two experiments that made this visible.
LeetCode: 510 AI-generated solutions. Every solution passed LeetCode’s test suite. Then I ran them through a six-pass pipeline — explain, extract beliefs, derive patterns, review adversarially, analyze contradictions. The pipeline found 17 real bugs the generator missed. Not theoretical concerns — concrete, fixable code-level bugs. binary_gap loops forever on negative input. pillowHolder(1, t) divides by zero. 52 functions named after the wrong problem.
The model knew about every one of these issues. It just didn’t activate that knowledge during generation.
DDIA: 37 reference implementations of distributed systems concepts. All generated from a table of contents — no source code provided. Then three rounds of belief-driven analysis found 30 bugs. The first round found a delete-before-rename bug that cascaded through 31 derived beliefs. By round 3, the pipeline was finding missing fsync calls, unguarded concurrency, and recovery paths that violated their own invariants.
Same model generated the code and found the bugs. Different passes, different questions, different knowledge activated.
What Came Out
Here’s what makes this interesting. The inputs were minimal:
| What I provided | What the pipeline extracted |
|---|---|
| DDIA table of contents | 37 implementations, 1,405 beliefs, 30 bugs, 7 architectural rules |
| LeetCode problem statements | 510 solutions, 1,641 beliefs, 17 bugs |
Everything beyond the seed inputs came from the model. The implementations, the beliefs, the bugs, the architectural rules — all extracted from parametric knowledge through repeated pipeline passes. Not retrieved from a document store. Not fine-tuned into weights. Mined from what the model already knew.
A single prompt (“implement a B-tree”) gets one trajectory. The pipeline runs six passes across the entire domain, producing hundreds of trajectories that collectively cover far more of what the model knows than any conversation could.
Six Passes, Six Layers of Knowledge
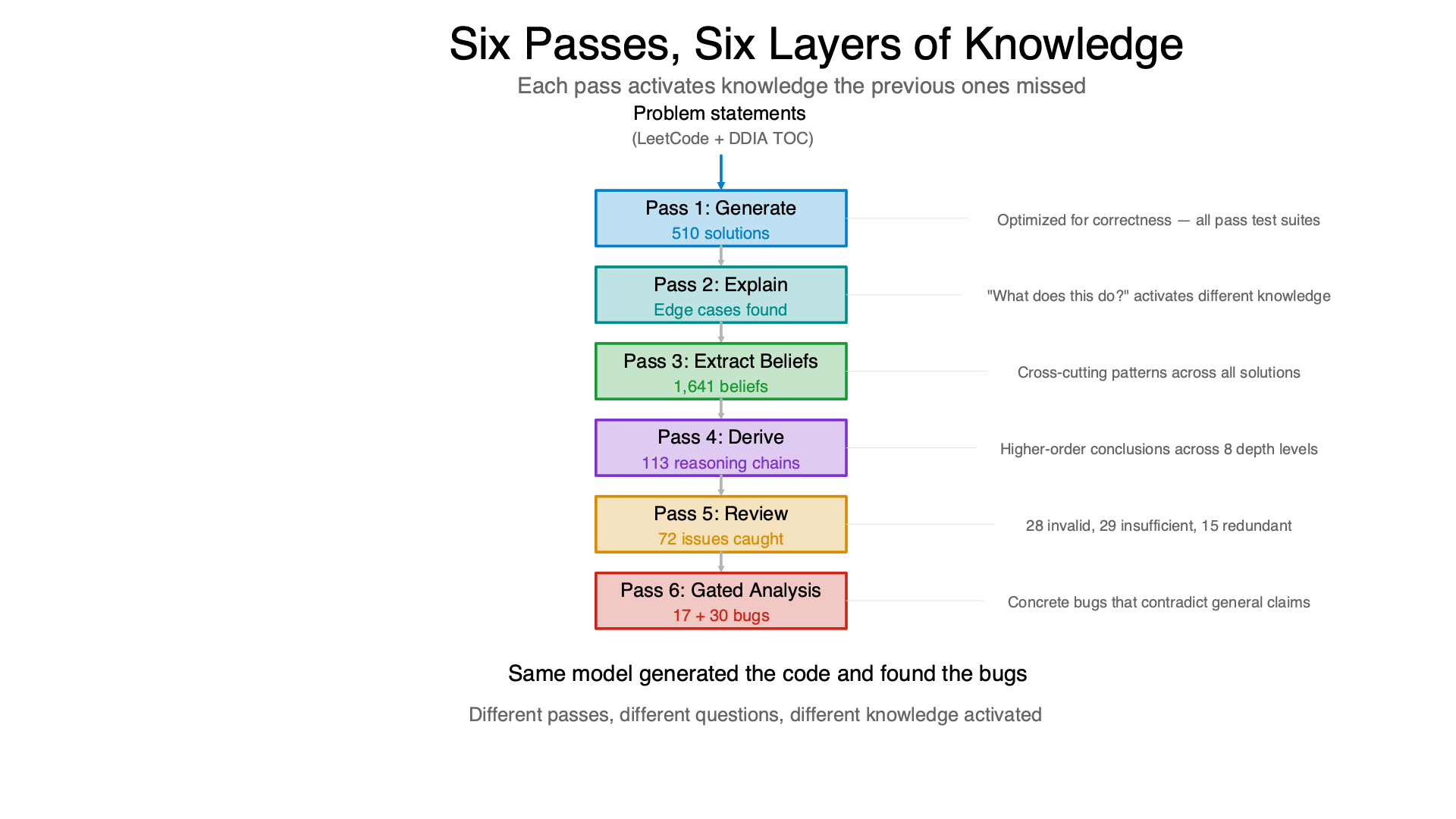
Each pass activated knowledge the previous ones missed:
Pass 1: Generate. Produce solutions optimized for correctness. All 510 passed their test suites.
Pass 2: Explain. Examine each solution and describe what it actually does. Found edge cases the generator didn’t consider — infinite loops, division by zero, incorrect names. The explainer sees things the generator didn’t because “what does this do?” is a different question than “make this work.”
Pass 3: Extract beliefs. Synthesize observations into patterns across all solutions. “Solutions never validate input.” “Correctness comes from construction, not validation.” “Single-pass streaming is the dominant shape.” 1,641 beliefs extracted — cross-cutting patterns invisible when looking at solutions one at a time.
Pass 4: Derive. Build reasoning chains from beliefs. Combine premises into higher-order conclusions: “quality inversion between algorithmic and engineering quality” — solutions that are algorithmically elegant are often engineering-fragile. 113 derived beliefs across 8 depth levels.
Pass 5: Review. Evaluate derivations adversarially. “Does this conclusion actually follow from these premises?” Found 28 invalid (conclusions don’t follow), 29 insufficient (overgeneralize), 15 unnecessary (redundant). The reviewer caught errors the deriver made — same model, different objective.
Pass 6: Gated analysis. The belief network identified concrete bugs that contradicted general claims. “We believe SSTable lookups are correct” is blocked by “SSTable has no sort-order enforcement.” That’s not a vague concern — it’s a specific line of code that contradicts a specific claim.
Why This Works
An LLM’s knowledge is a high-dimensional distribution, not a lookup table. A single forward pass samples one point from that distribution. The sample is shaped by the prompt, the context, and the framing.
“Write a solution” and “find bugs in this solution” activate different regions of the same distribution. Neither is wrong. Neither is complete. Together, they cover more of the space than either alone.
This is why the pipeline converges. Each round finds fewer new issues — not because it’s running out of bugs, but because it’s running out of unsampled knowledge for this domain. In the DDIA case, cascade impact per retraction declined from 4.1 (round 1) to 0.8 (round 3). The high-impact issues surface first because they sit at the base of the deepest reasoning chains.
The Human Parallel
This mirrors code review. A reviewer catches bugs the author missed, even when both have the same skill level. The author optimized for making it work. The reviewer optimizes for finding where it breaks. Same knowledge, different activation.
What the LLM case adds is scale and measurability. We can count exactly how many bugs each pass found. We can trace which beliefs gated which conclusions. We can measure convergence. The mechanism is the same as human code review, but the structured pipeline makes it systematic and auditable.
What To Do About It
If you’re using LLMs to generate anything — code, analysis, documentation, designs — you’re leaving knowledge on the table with a single pass. Here’s how to get more out:
1. Vary the angle. Don’t just re-run generation. Explain, then synthesize, then derive, then challenge. Each framing activates different knowledge.
2. Make contradictions structural. “I think there might be a bug” is vague. “This specific observation blocks this specific conclusion” is actionable. Build a structure where concrete observations can contradict general claims.
3. Measure convergence. Track how many new issues each round finds. When rounds stop finding issues, you’ve covered the model’s accessible knowledge for this domain.
4. Persist what you extract. Knowledge extracted through five passes and forgotten is wasted work. Store it in a format that survives sessions — justified beliefs with derivation chains, not conversation history that gets truncated.
5. Separate generate from critique. The generator’s job is to build. The reviewer’s job is to break. If the same pass does both, the “be helpful” objective suppresses the critical knowledge. Structural separation is what lets the model disagree with itself.
The model has the knowledge. Your pipeline determines how much of it you extract.
The pipeline described here is built on external epistemic memory — justified beliefs with retraction cascades that persist across sessions. The tools are open source: ftl-reasons (the engine) and expert-agent-builder (the pipeline).
Previously: Stop Fine-Tuning, Start Remembering, Seven Rules for Building Data-Intensive Systems, The Dirty Pipeline.